All Publications
 |
Self-Training Large Language Models for Improved Visual Program Synthesis Zaid Khan, Vijay Kumar, Samuel Schulter, Yun Fu, Manmohan Chandraker CVPR 2024 [PDF] [Project page] An LLM agent for visual program synthesis trainable with reinforced self-training using just weak supervision from vision-language tasks. |
 |
LidaRF: Delving into Lidar for Neural Radiance Field on Street Scenes Shanlin Sun, Bingbing Zhuang, Ziyu Jiang, Buyu Liu, Xiaohui Xie, Manmohan Chandraker CVPR 2024 [PDF] A Lidar-enhanced neural radiance field to transform drive videos into photorealistic sensor simulation testbeds. |
 |
TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion Yu-Ying Yeh, Jia-Bin Huang, Changil Kim, Lei Xiao, Thu Nguyen-Phuoc, Numair Khan, Cheng Zhang, Manmohan Chandraker, Carl S Marshall, Zhao Dong, Zhengqin Li CVPR 2024 [PDF] [Project page] Transfer photorealistic, high-fidelity and geometry-aware textures from 3-5 images to arbitrary 3D meshes. |
 |
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving Mingfu Liang, Jong-Chyi Su, Samuel Schulter, Sparsh Garg, Shiyu Zhao, Ying Wu, Manmohan Chandraker CVPR 2024 [PDF] A VLM and LLM-based framework for issue-finding, auto-labeling, continual training and automated verification for visual perception in autonomous driving. |
|
What You See Is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs Alex Trevithick, Matthew Chan, Towaki Takikawa, Umar Iqbal, Shalini De Mello, Manmohan Chandraker, Ravi Ramamoorthi, Koki Nagano CVPR 2024 [PDF] [Project page] Scale neural volume rendering to high resolution by rendering every pixel to ensure that "what you see in 2D, is what you get in 3D". |
|
 |
MCNeRF: Monte Carlo Rendering and Denoising for Real-Time NeRFs Kunal Gupta, Milos Hasan, Zexiang Xu, Fujun Luan, Kalyan Sunkavalli, Xin Sun, Manmohan Chandraker, Sai Bi SIGGRAPH Asia 2023 [PDF] [Project page] [Code] A general Monte Carlo volume rendering algorithm to accelerate any NeRF representation using importance sampling based on ray density distributions. |
 |
Spatiotemporally Consistent HDR Indoor Lighting Estimation Zhengqin Li, Li Yu, Mikhail Okunev, Manmohan Chandraker, Zhao Dong ToG 2023 [PDF] A physically-motivated deep network that predicts spatiotemporally consistent lighting given a single LDR video of an indoor scene. |
 |
Exploring Question Decomposition for Zero-Shot VQA Zaid Khan, Vijay Kumar, Samuel Schulter, Manmohan Chandraker, Raymond Fu NeurIPS 2023 [PDF] [Project page] [Code] Question decomposition that allows multi-billion scale vision-language models to approach reasoning-heavy visual question-answering as a two-step rather than a single-step problem. |
 |
NeurOCS: Neural NOCS Supervision for Monocular 3D Object Localization Zhixiang Min, Bingbing Zhuang, Samuel Schulter, Buyu Liu, Enrique Dunn, Manmohan Chandraker CVPR 2023 [PDF] Learn dense 3D object shapes for autonomous driving, using differentiable rendering with instance masks and 3D boxes, along with category-level priors. |
 |
GeoNet: Benchmarking Unsupervised Adaptation across Geographies Tarun Kalluri, Wangdong Xu, Manmohan Chandraker CVPR 2023 [PDF] [Project page] [Code] A large-scale dataset and study on the robustness of computer vision algorithms and large pre-trained models across geographical biases. |
 |
FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation Tarun Kalluri, Deepak Pathak, Manmohan Chandraker, Du Tran WACV 2023 [Best Paper Finalist] [PDF] [Project page] [Code] A flow-free and single-shot prediction approach for video frame interpolation, allowing efficient ultra-slow motion effects using just 3D convolutions. |
|
Factorized Inverse Path Tracing for Efficient and Accurate Material-Lighting Estimation Liwen Wu, Rui Zhu, Mustafa B. Yaldiz, Yinhao Zhu, Hong Cai, Janarbek Matai, Fatih Porikli, Tzu-Mao Li, Manmohan Chandraker, Ravi Ramamoorthi ICCV 2023 (Oral) [PDF] [Project page] [Code] Joint estimation of emitters and materials in inverse rendering, to enable high-quality AR applications like scene relighting and object insertion. |
|
 |
Q: How to Specialize Large VLMs to Data-Scarce VQA? A: Train on Unlabeled Images! Zaid Khan, Vijay Kumar, Samuel Schulter, Raymond Fu, Manmohan Chandraker Pseudo-label question-answers in unlabeled images, for fine-tuning an existing large vision-language model on visual question answering in a data-scarce target dataset. |
 |
A Theory of Topological Derivatives for Inverse Rendering of Geometry Ishit Mehta, Manmohan Chandraker, Ravi Ramamoorthi ICCV 2023 [PDF] [Project page] Inverse rendering through variational optimization of image functionals that allows for discrete topology changes by nucleating hole or phase changes, with applications to multiview 3D reconstruction and text-to-image generation. |
 |
Real-Time Radiance Fields for Single-Image Portrait View Synthesis Alex Trevithick, Matthew Chan, Michael Stengel, Eric R. Chan, Chao Liu, Zhiding Yu, Sameh Khamis, Manmohan Chandraker, Ravi Ramamoorthi, Koki Nagano SIGGRAPH 2023 [PDF] [Project page] A real-time 3D GAN with a ViT encoder to infer and render a photorealistic 3D representation from a single unposed image such as a face portrait. |
 |
Physically-Based Editing of Indoor Scene Lighting from a Single Image Zhengqin Li, Jia Shi, Sai Bi, Rui Zhu, Kalyan Sunkavalli, Milos Hasan, Zexiang Xu, Ravi Ramamoorthi, Manmohan Chandraker ECCV 2022 (Oral) [PDF] [Project page] [Code] [Video] Estimation of visible and invisible light sources from a single image of an indoor scene, to enable scene relighting and object insertion with full global effects. |
 |
A Level Set Theory for Neural Implicit Evolution under Explicit Flows Ishit Mehta, Manmohan Chandraker, Ravi Ramamoorthi ECCV 2022 (Oral) [Best Paper Honorable Mention] [PDF] [Project page] [Code] [Video] A level-set theory bridge between explicit and implicit shape representations that allows user-defined editing of neural implicit geometry. |
 |
MemSAC: Memory Augmented Sample Consistency for Large Scale Domain Adaptation Tarun Kalluri, Astuti Sharma, Manmohan Chandraker ECCV 2022 [PDF] [Project page] [Code] Unsupervised domain adaptation that scales to a large number of categories using a memory bank. |
 |
Learning Semantic Segmentation from Multiple Datasets with Label Shifts Dongwan Kim, Yi-Hsuan Tsai, Yumin Suh, Masoud Faraki, Sparsh Garg, Manmohan Chandraker, Bohyung Han ECCV 2022 [PDF] Semantic segmentation training across multiple datasets with differing label spaces for better generalization to unseen domains. |
 |
Exploiting Unlabeled Data with Vision and Language Models for Object Detection Shiyu Zhao, Zhixing Zhang, Samuel Schulter, Long Zhao, Vijay Kumar BG, Anastasis Stathopoulos, Manmohan Chandraker, Dimitris N. Metaxas ECCV 2022 [PDF] Object detection for unseen categories using pseudo-labels generated with large pre-trained vision-language models. |
 |
Single-Stream Multi-Level Alignment for Vision-Language Pretraining Zaid Khan, Vijay Kumar BG, Xiang Yu, Samuel Schulter, Manmohan Chandraker, Yun Fu ECCV 2022 [PDF] Single-stream architecture for aligning vision and language representations at instance, patch and semantic levels.. |
 |
TRoVE: Transforming Road Scene Datasets into Photorealistic Virtual Environments Shubham Dokania, Anbumani Subramanian, Manmohan Chandraker, C. V. Jawahar ECCV 2022 [PDF] Photorealistic virtual environments with high-quality multi-modal ground truth for geometry, material and semantics in road scenes. |
 |
IRISformer: Dense Vision Transformers for Single-Image Inverse Rendering in Indoor Scenes Rui Zhu, Zhengqin Li, Janarbek Matai, Fatih Porikli, Manmohan Chandraker CVPR 2022 (Oral) [PDF] [Project page] [Code] [Video] A vision transformer architecture for inverse rendering in indoor scenes that allows learning long-range global interactions. |
 |
PhotoScene: Photorealistic Material and Lighting Transfer for Indoor Scenes Rui Zhu, Zhengqin Li, Janarbek Matai, Fatih Porikli, Manmohan Chandraker CVPR 2022 [PDF] [Project page] [Code] [Video] A framework that uses a set of images of an indoor scene to create a photorealistic digital twin with high-quality material and lighting. |
 |
Weakly But Deeply Supervised Occlusion-Reasoned Parametric Layouts Buyu Liu, Bingbing Zhuang, Manmohan Chandraker CVPR 2022 [PDF] Single-image occlusion-reasoned road layout estimation in both perspective and parametric top-view space. |
 |
On Generalizing Beyond Domains in Cross-Domains Continual Learning Christian Simon, Masoud Faraki, Yi-Hsuan Tsai, Xiang Yu, Samuel Schulter, Yumin Suh, Mehrtash Harandi, Manmohan Chandraker CVPR 2022 [PDF] A continual learning method that allows generalization to new tasks in new domains with limited labels. |
 |
Learning to Learn across Diverse Data Biases in Deep Face Recognition Chang Liu, Xiang Yu, Yi-Hsuan Tsai, Masoud Faraki, Ramin Moslemi, Manmohan Chandraker, Yun Fu CVPR 2022 [PDF] Meta-learning to address biases due to long-tailed data and factors of variation such as ethnicity, head pose, occlusion and blur. |
 |
Controllable Dynamic Multi-Task Architectures Dripta S. Raychaudhuri, Yumin Suh, Samuel Schulter, Xiang Yu, Masoud Faraki, Amit K. Roy-Chowdhury, Manmohan Chandraker CVPR 2022 (Oral) [PDF] Multi-task learning with a dynamic architecture that satisfies resource constraints and user preferences. |
 |
Cluster-To-Adapt: Few Shot Domain Adaptation for Semantic Segmentation Across Disjoint Labels Tarun Kalluri, Manmohan Chandraker CVPR 2022 [PDF] A clustering objective enforced in a transformed feature space for domain adaptation across segmentation datasets with completely different categories. |
 |
Modulated Periodic Activations for Generalizable Local Functional Representations Ishit Mehta, Michael Gharbi, Connelly Barnes, Eli Shechtman, Ravi Ramamoorthi, Manmohan Chandraker ICCV 2021 [PDF] [Project page] [Code] Local functional representations that encode signals while achieving both high accuracy and generalization ability. |
 |
Learning Cross-Modal Contrastive Features for Video Domain Adaptation Donghyun Kim, Yi-Hsuan Tsai, Bingbing Zhuang, Xiang Yu, Stan Sclaroff, Kate Saenko, Manmohan Chandraker ICCV 2021 [PDF] Unsupervised domain adaptation for video representations in action recognition by aligning features across color and optical flow modalities. |
 |
OpenRooms: An End-to-End Open Framework for Photorealistic Indoor Scene Datasets Zhengqin Li, Ting-Wei Yu, Shen Sang, Sarah Wang, Meng Song, Yuhan Liu, Yu-Ying Yeh, Rui Zhu, Nitesh Gundavarapu, Jia Shi, Sai Bi, Hong-Xing Yu, Zexiang Xu, Kalyan Sunkavalli, Milos Hasan, Ravi Ramamoorthi, Manmohan Chandraker CVPR 2021 (Oral) [PDF] [Project page] [Code] [Video] An open source dataset of indoor scenes with high-quality tools and ground truth for shape, material and lighting, for augmented reality and robotics applications. |
 |
Divide-and-Conquer for Lane-Aware Diverse Trajectory Prediction Sriram Narayanan, Ramin Moslemi, Francesco Pittaluga, Buyu Liu, Manmohan Chandraker CVPR 2021 (Oral) [PDF]A multi-choice learning objective for diverse future trajectory prediction and a lane anchor network for 3D scene-consistent outputs. |
 |
Instance Level Affinity-Based Transfer for Unsupervised Domain Adaptation Astuti Sharma, Tarun Kalluri, Manmohan Chandraker CVPR 2021 [PDF]An instance-affinity based criterion with a multi-sample contrastive loss for improved domain alignment. |
 |
Fusing the Old with the New: Learning Relative Camera Pose with Geometry-Guided Uncertainty Bingbing Zhuang, Manmohan Chandraker CVPR 2021 (Oral) [PDF]A probabilistic fusion that learns to account for relative uncertainties in pose estimation by traditional geometric methods and deep neural networks, to achieve both better generalization and handling of ambiguities. |
 |
Looking Farther in Parametric Scene Parsing with Ground and Aerial Imagery Raghava Modhugu, Harish Sethuram, Manmohan Chandraker, C.V. Jawahar ICRA 2021 [PDF] Road scene parsing in bird-eye view combining the relative benefits of ground-based proximate images with aerial remote sensing inputs. |
 |
Neural Mesh Flow: 3D Manifold Mesh Generation via Diffeomorphic Flows Kunal Gupta, Manmohan Chandraker NeurIPS 2020 [PDF] Neural ODEs to generate 3D meshes with guaranteed manifoldness, enabling physically meaningful applications like rendering, simulations and 3D printing. |
 |
Single-Shot Neural Relighting and SVBRDF Estimation Shen Sang, Manmohan Chandraker ECCV 2020 [PDF] A physically-motivated network for joint shape and material estimation, as well as relighting under novel illumination conditions, using a single image captured by a mobile phone camera. |
 |
SMART: Simultaneous Multi-Agent Recurrent Trajectory Prediction Sriram Narayanan, Francesco Pittaluga, Buyu Liu, Manmohan Chandraker ECCV 2020 [PDF] Constant-time, scene consistent and diverse trajectory prediction regardless of number of agents, along with a dynamics simulator that diversifies top-views of real scenes. |
 |
Single-View Metrology in the Wild Rui Zhu, Xingyi Wang, Yannick Hold-Geoffroy, Federico Perazzi, Jonathan Eisenmann, Kalyan Sunkavalli, Manmohan Chandraker ECCV 2020 [PDF] Recover object height and camera parameters from a single unconstrained image, through a network that imbibes weakly supervised geometric constraints through bounding boxes and the horizon. |
 |
Improving Face Recognition by Clustering Unlabeled Faces in the Wild Aruni RoyChowdhury, Xiang Yu, Kihyuk Sohn, Erik Learned-Miller, Manmohan Chandraker ECCV 2020 [PDF] A clustering method to improve face recognition using unlabeled data, exploiting extreme value theory to account for overlapping identies between labeled and unlabeled data. |
 |
Learning Monocular Visual Odometry via Self-Supervised Long-Term Modeling Yuliang Zou, Pan Ji, Quoc-Huy Tran, Jia-Bin Huang, Manmohan Chandraker ECCV 2020 [PDF] A two-layer convolutional LSTM that uses insights from keyframe-based methods to learn visual odometry from very long monocular sequences, in contrast to prior methods that are limited to short snippets. |
 |
Pseudo RGB-D for Self-Improving Monocular SLAM and Depth Prediction Lokender Tiwari, Pan Ji, Quoc-Huy Tran, Bingbing Zhuang, Saket Anand, Manmohan Chandraker ECCV 2020 [PDF] A self-improving framework for monocular SLAM that iterates between unsupervised depth estimation and robust geometric SLAM to achieve state-of-the-art on KITTI and TUM sequences. |
 |
Domain Adaptive Semantic Segmentation Using Weak Labels Sujoy Paul, Yi-Hsuan Tsai, Samuel Schulter, Amit K. RoyChowdhury, Manmohan Chandraker ECCV 2020 [PDF] Domain adaptation that uses weak image-level labels to achieve category-wise alignment despite distribution shifts in dense structured prediction problems like semantic segmentation. |
 |
Object Detection with a Unified Label Space from Multiple Datasets Xiangyun Zhao, Samuel Schulter, Gaurav Sharma, Yi-Hsuan Tsai, Manmohan Chandraker, Ying Wu ECCV 2020 [PDF] A method for training a single object detector across multiple datasets, despite overlaps or mismatches between their label spaces. |
 |
Through the Looking Glass: Neural 3D Reconstruction of Transparent Shapes Zhengqin Li, Yu-Ying Yeh, Manmohan Chandraker CVPR 2020 (Oral) [PDF] A physically-motivated network that models refractions and reflections to recover high-quality 3D geometry for complex transparent shapes using as few as 5-12 natural images. |
 |
Inverse Rendering for Complex Indoor Scenes: Shape, Spatially-Varying Lighting and SVBRDF from a Single Image Zhengqin Li, Mohammad Shafiei, Ravi Ramamoorthi, Kalyan Sunkavalli, Manmohan Chandraker CVPR 2020 (Oral) [PDF] A physically-motivated network that recovers shape, complex material and spatially varying lighting from a single mobile phone image to enable photorealistic indoor AR applications. |
 |
Peek-a-Boo: Occlusion Reasoning in Indoor Scenes with Plane Representations Ziyu Jiang, Buyu Liu, Samuel Schulter, Zhangyang Wang, Manmohan Chandraker CVPR 2020 (Oral) [PDF] A novel planar representation for indoor 3D scene understanding that reasons about occlusions, with new metrics and a new dataset. |
 |
Towards Universal Representation Learning for Deep Face Recognition Yichun Shi, Xiang Yu, Kihyuk Sohn, Manmohan Chandraker, Anil K. Jain CVPR 2020 [PDF] A universal representation for face recognition that achieves robustness and accuracy across several factors of variation such as blur, resolution and occlusion. |
 |
Understanding Road Layout from Videos as a Whole Buyu Liu, Bingbing Zhuang, Samuel Schulter, Pan Ji, Manmohan Chandraker CVPR 2020 [PDF] Predict top-view layout of a complex 3D scene using a video sequence as input, with spatial consistency among objects and scene elements, as well as temporal coherence. |
 |
Private-kNN: Practical Differential Privacy for Computer Vision Yuqing Zhu, Xiang Yu, Manmohan Chandraker, Yu-Xiang Wang CVPR 2020 [PDF] Making differential privacy practical for computer vision by reducing more than 90% privacy cost compared to prior methods, while achieving better accuracy. |
 |
Active Adversarial Domain Adaptation Jong-Chyi Su, Yi-Hsuan Tsai, Kihyuk Sohn, Buyu Liu, Subhransu Maji, Manmohan Chandraker WACV 2020 [PDF] An active learning framework by integrating domain adversarial learning and importance sampling for continuous semi-supervised domain adaptation, applied to object recognition and detection. |
 |
DAVID: Dual-Attentional Video Deblurring Junru Wu, Xiang Yu, Ding Liu, Manmohan Chandraker, Zhangyang Wang WACV 2020 [PDF] Video deblurring with an internal attention module to select optimal temporal scales for restoring the sharp center frame and an external attention module to aggregate such estimates across different blur levels. |
 |
Unsupervised and Semi-Supervised Domain Adaptation for Action Recognition from Drones Jinwoo Choi, Gaurav Sharma, Manmohan Chandraker, Jia-Bin Huang WACV 2020 [PDF] Action recognition on drone videos without using labeled data, through adversarial domain adaptation to labeled Internet video datasets. |
 |
Adversarial Learning of Privacy-Preserving and Task-Oriented Representations T. Xiao, Y.-H. Tsai, K. Sohn, M.K. Chandraker, M.-H. Yang AAAI 2020 [PDF] Learning deep features that protect against model inversion attacks by an adversary with access to large-scale public data, with application to facial attribute recognition while protecting identity. |
 |
EcSeg: Semantic Segmentation of Metaphase Images Containing Extrachromosomal DNA Utkrisht Rajkumar, Kristen Turner, Jens Luebeck, Viraj Deshpande, Manmohan Chandraker, Paul Mischel, Vineet Bafna iScience 2019 [PDF] Semantic segmentation for automatic microscopy image analysis to quantify oncogenes located on extrachromosomal DNA. |
 |
Universal Semi-Supervised Semantic Segmentation T. Kalluri, G. Varma, M.K. Chandraker and C.V. Jawahar ICCV 2019 [PDF] Learning fair representations that perform well across both data-rich and data-poor domains, applied to semantic segmentation that minimizes annotation and deployment costs. |
 |
Domain Adaptation for Structured Output via Disentangled Patch Representations Y.-H. Tsai, K. Sohn, S. Schulter and M.K. Chandraker ICCV 2019 (Oral) [PDF] Unsupervised domain adaptation for semantic segmentation by learning discriminative feature representations of patches in the source domain that correspond to modes of the output space distribution. |
 |
A Parametric Top-View Representation of Complex Road Scenes Z. Wang, B. Liu, S. Schulter and M.K. Chandraker CVPR 2019 [PDF] A parametric representation for 3D scene understanding of complex road scenes that is intuitive for human visualization and interpretable for higher-level decision making. |
 |
Feature Transfer Learning for Face Recognition with Under-Represented Data X. Yin, X. Yu, K. Sohn, X. Liu and M.K. Chandraker CVPR 2019 [PDF] Mitigating bias against under-represented categories in face recognition by augmenting the feature space of under-represented subjects using the distribution of features for subjects that have sufficiently diverse samples. |
 |
Learning Structure-And-Motion-Aware Rolling Shutter Correction B. Zhuang, Q.-H. Tran, P. Ji, L.F. Cheong and M.K. Chandraker CVPR 2019 [PDF] Theoretical limits on SFM with a rolling-shutter camera and leveraging data-driven priors through a network that learns camera motion and scene stucture to undistort a single rolling shutter image. |
 |
Joint Pixel and Feature-Level Domain Adaptation for Recognition in the Wild L. Tran, K. Sohn, X. Yu, X. Liu, and M.K. Chandraker CVPR 2019 [PDF] [Supplementary] Unsupervised domain adaptation that combines insights from semi-supervised learning for feature-level adaptation and 3D geometry-guided image synthesis for pixel-level adaptation. |
 |
Learning to Simulate N. Ruiz, S. Schulter and M.K. Chandraker ICLR 2019 [PDF] A reinforcement learning-based method for automatically adjusting the parameters of any non-differentiable simulator, thereby controlling the distribution of synthesized data in order to maximize the accuracy of a model trained on that data. |
 |
Unsupervised Domain Adaptation for Distance Metric Learning K. Sohn, W. Shang, X. Yu and M.K. Chandraker ICLR 2019 [PDF] Making face recognition fair across ethnicities through unsupervised adaptation across domains with non-overlapping label spaces, retaining identification power on all ethnicities while keeping representations for all identities well-separated. |
 |
Single-Shot Analysis of Refractive Shapes Using Convolutional Neural Networks J. Stets, Z. Li, J. Frisvad and M.K. Chandraker WACV 2019 [PDF] Single-image depth map and normal estimation for transparent shapes using a network trained on a new synthetic dataset. |
 |
AutoNUE: A Dataset for Exploring Problems of Autonomous Navigation in Unconstrained Environments G. Varma, A. Subramanian, A. Namboodiri, M.K. Chandraker and C.V. Jawahar WACV 2019 [PDF] Taking a step towards self-driving on Indian roads through a novel large-scale dataset that provides instance segmentation and object detection labels. |
 |
Memory Warps for Learning Long-Term Online Video Representations T.-H. Vu, S. Schulter, W. Choi and M.K. Chandraker WACV 2019 [PDF] A memory-based online video representation that achieves efficiency and accuracy through spatiotemporal warping to compensate for motions, while enabling prediction of feature representations in future frames. |
 |
Learning to Reconstruct Shape and Spatially-Varying Reflectance with a Single Image Z. Li, Z. Xu, R. Ramamoorthi, K. Sunkavalli and M.K. Chandraker SIGGRAPH Asia 2018 [PDF] A differential rendering layer with global illumination to train a network that recovers shape and complex, spatially-varying material using a single image acquired with a mobile phone camera. |
 |
Materials for Masses: SVBRDF Acquisition with a Single Mobile Phone Image Z. Li, K. Sunkavalli and M.K. Chandraker ECCV 2018 (Oral) [PDF] A differentiable rendering layer that models image formation with a complex spatially-varying BRDF to recover high-quality material information using a single mobile phone image. |
 |
Learning to Look around Objects for Top-View Representations of Outdoor Scenes S. Schulter, M. Zhai, N. Jacobs and M.K. Chandraker ECCV 2018 [PDF] Predict occluded portions of the scene layout by looking around foreground objects like cars or pedestrians, with learned priors and rules about typical road layouts from simulated or, if available, map data. |
 |
Hierarchical Metric Learning and Matching for 2D and 3D Geometric Correspondences M. Fathy, Q.-H. Tran, Z. Zia, P. Vernaza and M.K. Chandraker ECCV 2018 [PDF] Metric learning and deep supervision to leverage feature hierarchies in a deep convolutional network for 2D and 3D geometric matching. |
 |
Learning to Adapt Structured Output Space for Semantic Segmentation Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang and M.K. Chandraker CVPR 2018 (Spotlight) [PDF] Unsupervised domain adaptation for semantic segmentation that aligns spatial similarities across domains through a structured output space. |
 |
Learning to See through Turbulent Water Z. Li, Z. Murez, D. Kriegman, R. Ramamoorthi and M.K. Chandraker WACV 2018 [PDF] Learning appearance and geometric priors for single-image undistortion of an image observed through a dynamic refractive medium such as water waves. |
 |
Learning Efficient Object Detection Models with Knowledge Distillation G. Chen, W. Choi, X. Yu, T. Han and M.K. Chandraker NeurIPS 2017 [PDF] Fast and accurate object detection network through knowledge distillation that transfers insights to a compact student model from a higher-capacity teacher model. |
 |
Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos K. Sohn, S. Liu, G. Zhong, X. Yu, M.-H. Yang and M.K. Chandraker ICCV 2017 [PDF] Video face recognition that utilizes large-scale unlabeled video data for adversarial domain alignment while transferring discriminative knowledge from large-scale labeled still images. |
 |
Towards Large-Pose Face Frontalization X. Yin, X. Yu, K. Sohn, X. Liu and M.K. Chandraker ICCV 2017 [PDF] A GAN that utilizes 3D geometric priors to frontalize a profile view of a face, achieving high quality as well as maintaining identity. |
 |
Feature Reconstruction-Based Disentanglement for Pose-Invariant Face Recognition X. Peng, X. Yu, K. Sohn, D. Metaxas and M.K. Chandraker ICCV 2017 [PDF] Metric learning to explicitly disentangle identity and pose, by demanding alignment between feature reconstructions through various combinations of identity and pose features. |
 |
Weakly Supervised Generative Adversarial Networks for 3D Reconstruction J. Gwak, C. Choy, A. Garg, M.K. Chandraker and S. Savarese 3DV 2017 [PDF] Weakly supervised 3D reconstruction using silhouettes through a raytrace pooling layer that enables perspective projection and backpropagation, along with an adversarial constraint. |
 |
Robust Energy Minimization for BRDF-Invariant Shape from Light Fields Z. Li, Z. Xu, R. Ramamoorthi and M.K. Chandraker CVPR 2017 [PDF] A variational energy minimization framework for robust recovery of shape in multiview stereo with unknown BRDF, with applications to light field cameras. |
 |
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing C. Li, Z. Zia, Q.-H. Tran, X. Yu, G. Hager and M.K. Chandraker CVPR 2017 [PDF] Deep supervision to sequentially infer intermediate concepts associated with the final task allows better generalization, demonstrated with an application to 3D semantic parsing from 2D images. |
 |
DESIRE: Distant Future Prediction in Dynamic Scenes with Multiple Interacting Agents N. Lee, W. Choi, P. Vernaza, C. Choy, P. Torr and M.K. Chandraker CVPR 2017 [PDF] Predicting future trajectories in complex 3D scenes by accounting for the multimodaility of future behaviors, scene semantics and interactions among objects. |
 |
Deep Network Flow for Multi-Object Tracking S. Schulter, P. Vernaza, W. Choi and M.K. CHandraker CVPR 2017 [PDF] Learning differentiable cost functions for multi-target tracking by association, with a bilevel optimization to minimize a loss defined on the solution of a liner program. |
 |
Person Re-Identification in the Wild L. Zheng, H. Zhang, S. Sun, M.K. Chandraker, Y. Yang and Q. Tian CVPR 2017 [PDF] The PRW dataset, methods and metrics for jointly performing person detection and re-identification in videos. |
 |
Universal Correspondence Network C. Choy, J. Gwak, S. Savarese and M.K. Chandraker NeurIPS 2016 (Oral) [PDF] Deep metric learning to learn a feature space for geometric and semantic correspondence, with novel architectures such as a convolutional spatial transformer to handle local variations. |
 |
Deep Deformation Network for Object Landmark Localization X. Yu, F. Zhou and M.K. Chandraker ECCV 2016 [PDF] Landmark localization for non-rigid objects by incorporating geometric insights such as shape bases and thin-plate spline deformations in a deep convolutional network. |
 |
A 4D Light-Field Dataset and CNN Architectures for Material Recognition T.-C. Wang, E. Hiroaki, J. Zhu, M.K. Chandraker, A. Efros and R. Ramamoorthi ECCV 2016 [PDF] A dataset of light field images and novel 4D convolutional architectures to improve material recognition by exploiting multiple sub-aperture views and view-dependent reflectance effects. |
 |
WarpNet: Weakly Supervised Matching for Single-View Reconstruction A. Kanazawa, D. Jacobs and M.K. Chandraker CVPR 2016 [PDF] Single-view reconstruction of non-rigid objects like birds without using part annotations, through a deformation-aware synthetic data generation and spatial priors in a deep network. |
 |
SVBRDF-Invariant Shape and Reflectance Recovery from Light Fields T.-C. Wang, M.K. Chandraker, A. Efros and R. Ramamoorthi CVPR 2016 (Oral) [PDF] Shape and spatially-varying material recovery from a single light field image of an object, using theoretical invariants from differential stereo with general reflectance. |
 |
A Continuous Occlusion Model for Road Scene Understanding V. Dhiman, Q.-H. Tran, J. Corso and M.K. Chandraker CVPR 2016 [PDF] Interpretable occlusion reasoning for 3D scene understanding that assigns points to objects by modeling reflection or transmission probabilities for the corresponding camera ray. |
 |
Atomic Scenes for Scalable Traffic Scene Recognition C.-Y. Chen, W. Choi and M.K. Chandraker WACV 2016 [PDF] Scalable framework for monocular 3D scene understanding with a hierarchical model that captures co-occurence and mutual exclusion relationships while incorporating both low-level trajectory features and high-level scene features. |
 |
The Information Available to a Moving Observer on Shape with Unknown, Isotropic BRDFs M.K. Chandraker IEEE PAMI 2015 [Spl. Issue, Best of CVPR 2014] [PDF] Theoretical inavriants that eliminate BRDF from a system of differential stereo equations to yield PDE constraints that delineate the extent of shape recovery. |
 |
High Accuracy Monocular SFM and Scale Correction for Autonomous Driving S. Song, M.K. Chandraker and C. Guest IEEE PAMI 2015 [PDF] Robust monocular SFM in road scenes through novel designs for long-term feature tracking and scale drift correction. |
 |
Joint SFM and Detection Cues in 3D Object Localization for Autonomous Driving S. Song and M.K. Chandraker CVPR 2015 (Oral) [PDF] Single-camera 3D localization of objects in traffic scenes by combining cues from SFM point tracks and object detection bounding boxes. |
 |
On Joint Shape and Material Recovery from Motion Cues M.K. Chandraker ECCV 2014 [PDF] Differential invariants under object or camera motion that constrain shape recovery or material estimation under various conditions on camera, material or lighting. |
 |
What Camera Motion Reveals About Shape with Unknown BRDF M.K. Chandraker CVPR 2014 (Oral) [Best Paper Award] [PDF] [Tech Report] Specification of the extent of shape recovery through differential stereo invariants obtained using images of an object with unknown material observed under a small camera motion. |
 |
Robust Scale Estimation in Real-Time Monocular SFM for Autonomous Driving S. Song and M.K. Chandraker CVPR 2014 [PDF] Scale drift correction in monocular SFM using cues such as sparse features, dense stereo and object bounding boxes, by relating observation covariances of cues to error behaviors of their underlying variables. |
 |
What Motion Reveals About Shape with Unknown BRDF and Lighting M.K. Chandraker, D. Reddy, Y. Wang and R. Ramamoorthi CVPR 2013 (Oral) [PDF] Theoretical analysis of shape recovery using differential flow invariants obtained under small motions of an object relative to its environment. |
 |
Dense Object Reconstruction with Semantic Priors Y. Bao, M.K. Chandraker, Y. Lin and S. Savarese CVPR 2013 (Oral) [PDF] Semantic 3D reconstruction using shape priors consisting of a mean shape for the commonality of shapes across a category and weighted anchor points to encode similarities between instances in the form of appearance and spatial consistency. |
 |
Parallel, Real-Time Monocular Visual Odometry S. Song and M.K. Chandraker ICRA 2013 [PDF] The first demonstration of practical monocular visual odometry in extended traffic scenes, through novel multithreaded design for robust feature tracking and scale drift correction. |
 |
On Differential Photometric Reconstruction for Unknown, Isotropic BRDFs M.K. Chandraker, J. Bai and R. Ramamoorthi IEEE PAMI 2013 [Spl. Issue, Best of CVPR 2011] [PDF] A photometric flow relation that specifies theoretical extent of shape recovery possible with differential motion of a light source. |
 |
What An Image Reveals About Material Reflectance M.K. Chandraker and R. Ramamoorthi ICCV 2011 (Oral) [PDF] A semiparametric regression for single-image material estimation that achieves better generalization and interpretability, enabling applications such as relighting and material editing. |
 |
A Theory of Photometric Reconstruction for Unknown Isotropic Reflectances M.K. Chandraker, J. Bai and R. Ramamoorthi CVPR 2011 (Oral) [PDF] Differential invariants under light source motion that determine the extent of shape recovery and prior information needed for it, using images of an object with unknown material. |
 |
On the Duality of Forward and Inverse Light Transport M.K. Chandraker, J. Bai, T.-T. Ng and R. Ramamoorthi IEEE PAMI 2011 [PDF] Fast computational methods for light transport inversion through a duality with forward rendering that allows analogues to radiosity, Monte Carlo and wavelet-based methods. |
 |
Globally Optimal Algorithms for Stratified Autocalibration M.K. Chandraker, S. Agarwal, D.J. Kriegman and S. Belongie IJCV 2009 [PDF] Tight convex relations in a branch and bound framework for globally optimal estimation of the plane at infinity with chirality constraints and dual image of the absolute conic with semidefinite constraints, allowing metric upgrade of a projective reconsturction. |
 |
A Dual Theory of Inverse and Forward Light Transport J. Bai, M.K. Chandraker, T.-T. Ng and R. Ramamoorthi ECCV 2010 [PDF] [Tech Report] [Project Site] Establishes light transport inversion as the dual problem of forward rendering, enabling efficient new methods for projector radiometric compensation and separation of bounces of global illumination. |
 |
Moving in Stereo: Efficient Structure and Motion Using Lines M.K. Chandraker, J. Lim and D.J. Kriegman ICCV 2009 [PDF] A fast solution for structure and motion from line correspondences through an overdetermined polynomial system, used in a robust RANSAC framework for line-based SFM. |
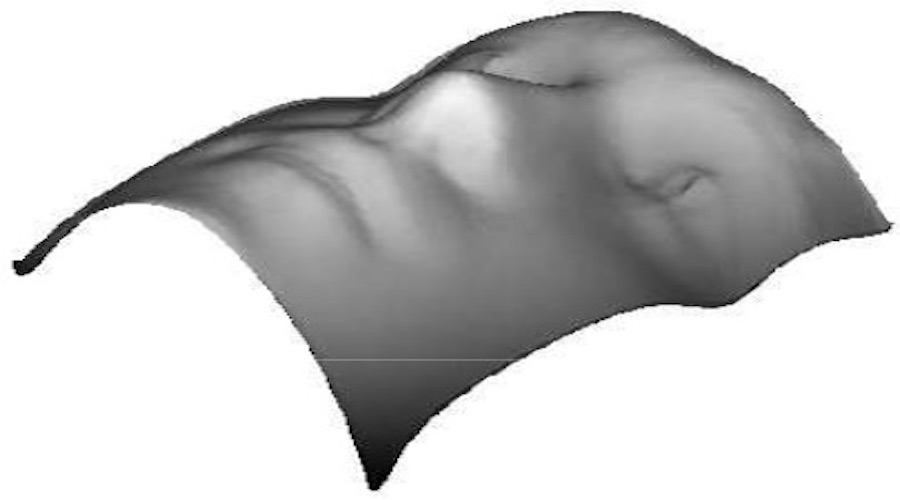 |
Globally Optimal Bilinear Programming for Computer Vision Applications M.K. Chandraker and D.J. Kriegman CVPR 2008 (Oral) [PDF] [Code] Globally optimal solutions to bilinear problems through convex relations in a branch and bound framework, demonstrated for face 3D morphable model fitting and non-rigid SFM. |
 |
Practical Global Optimization for Multiview Geometry F. Kahl, S. Agarwal, M.K. Chandraker, D.J. Kriegman and S. Belongie IJCV 2008 [PDF] [Code] Insights from fractional programming and the theory of convex underestimators for globally optimal solutions in multiview geometry under the standard L2-norm of reprojection errors and the L1-norm which is less sensitive to outliers. |
 |
Globally Optimal Affine and Metric Upgrades in Stratified Autocalibration M.K. Chandraker, S. Agarwal, D.J. Kriegman and S. Belongie ICCV 2007 (Oral) [Marr Prize Honorable Mention] [PDF] [Project Site] Globally optimal metric upgrade of a projective reconstruction, through efficient convex relaxations for estimating the plane at infinity and camera intrinsic parameters. |
 |
High Precision Multi-touch Sensing on Surfaces using Overhead Cameras A. Agarwal, S. Izadi, M.K. Chandraker and A. Blake IEEE Tabletop 2007 [PDF] Enable multi-touch interactions on an arbitrary flat surface using a pair of cameras mounted above the surface, by robustly identifying fingertips and precisely detecting touch. |
 |
ShadowCuts: Photometric Stereo with Shadows M.K. Chandraker, S. Agarwal and D.J. Kriegman CVPR 2007 [PDF] [Data+Code] An algorithm for performing Lambertian photometric stereo in the presence of shadows. It reduces the low frequency bias inherent to the normal integration process and ensures that the recovered surface is consistent with the shadowing configuration. |
 |
Autocalibration via Rank-Constrained Estimation of the Absolute Quadric M.K. Chandraker, S. Agarwal, F. Kahl, D. Nistér and D.J. Kriegman CVPR 2007 [PDF] [VRML] An autocalibration algorithm for upgrading a projective reconstruction to a metric reconstruction by estimating the absolute dual quadric. |
 |
Practical Global Optimization for Multiview Geometry S. Agarwal, M.K. Chandraker, F. Kahl, D.J. Kriegman and S. Belongie ECCV 2006 (Oral) [PDF] [Code] A practical method for finding the provably globally optimal solution to numerous problems in projective geometry including multiview triangulation, camera resectioning and homography estimation. |
 |
Reflections on the Generalized Bas-Relief Ambiguity M.K. Chandraker, F. Kahl and D.J. Kriegman CVPR 2005 (Oral) [PDF] For general nonconvex surfaces, interreflections completely resolve the GBR ambiguity. The full Euclidean geometry can be recovered from uncalibrated photometric stereo for which the light source directions and strengths are unknown. |
 |
Real-Time Camera Pose in a Room M.K. Chandraker, C. Stock and A. Pinz ICVS 2003 [PDF] A new, fully mobile, purely vision-based pose tracking system that works indoors in a prepared room, using artificial landmarks. |
 |
Subpixel Corner Detection for Tracking Applications using CMOS Camera Technology C. Stock, U. Mühlmann, M.K. Chandraker and A. Pinz AAPR 2002 [PDF] A multistage approach to gray-level corner detection that detects corners as the intersection points of the involved edges only by using a small neighborhood of the estimated corner position. |