Role of Files and File Systems, Storage Allocation, FS Implementation
Files
Before discussing file systems, it makes sense to discuss files.
What is a file? Think back to the beginning of the semester when
we discussed the first of many abstractions -- the process. We said that
a process is an abstracton for a unit of work to be managed by the
operating system system on behalf of some user (a person, an agent, or some
aspect of the system). We said that the PCB was an operating system data
structure that represented a process within the operating system.
Similarly, a file is an abstraction. It is a collection of data that
is organized by its users. The data within the file isn't necessarily
meaningful to the OS, the OS many not know how it is organized -- or even
why some collection of bytes have been organized together as a file.
None-the-less, it is the job of the operating system to provide a convenient
way of locating each such collection of data and manipulating it, while
protecting it from unintended or malicious damage by those who should not
have access to it, and ensuring its privacy, as appropriate.
Introduction: File Systems
A file system is nothing more than the component of the operating
system charged with managing files. It is responsible for interacting
with the lower-level IO subsystem used to access the file data, as well as
managing the files, themselves, and providing the API by which application
programmers can manipulate the files.
Factors In Filesystem Design
- naming
- operations
- storage layout
- failure resiliance
- efficiency (lost space is not recovered when a process ends as it is
with RAM, the penalty is also higher for frequent access...by a
factor of 106)
- sharing and concurrency
- protection
Naming
The simplest type of naming scheme is a flat space of objects. In this
model, there are only two real issues: naming and aliasing.
Naming involves:
- Syntax/format of names
- Legal characters
- Upper/lower case issues
- Length of names
- &c
Aliasing
Aliasing is the ability to have more than one name for the same file.
If aliasing is to be permitted, we must detemrine what types. It is useful
for several reasons:
- Some programs expect certain names. Sharing the name between two
such programs is painful without aliasing.
- Manual version management: foo.1, foo.2, foo.3
- Convenience of user -- several file can appear in several places near
things that relate to it.
There are two basic types:
- early binding: the target of the name is determined at the time
the link is created. In UNIX aliases that are bound early are called
hard links.
- late binding: The target is redetermined on each use, not once.
That is to say the target is bound to the name every time it is used. In
UNIX aliases that are bound late are called soft links or
symbolic links. Symbolic links can dangle, that is to say
that they can reference an object that has been destroyed.
In order to implement hard links, we must have low level names.
- invarient across renaming
- no aliasing of low level names
- each file has exactly 1 low-level name and at least 1 low level
name (The link count is the number of high level names associated
with a single low-level name.)
- the OS must ensure that the link count is 0 before removing a file (and
no one can have it open)
UNIX has low-level names, they are called inodes. The pair (device
number, inode # is unique). The inode also serves as the data structure
that represents the file within the OS, keeping track of all of its metadata.
In contrast, MS-DOS uniquely names files by their location on disk -- this
scheme does not allow for hard links.
Hierarchical Naming
Real systems use hierarchical names, not flat names. The reason for
this relates to scale. The human mind copes with large scale in
a hierarchical fashion.It is essentially a human cognative limitation,
we deal with large numbers of things by categorizing the. Every large
human organization is hierarchical: army, companies, church, etc.
Furthermore, too many names are hard to remember and it can be hard
to generate unique names.
With a hierarchical name space only a small fraction of the full
namespace is visible at any level. Internal nodes are directories and leaf
nodes are files. The pathname is a representation of the path from
the leafnode to the root of the tree.
The process of translating a pathname is known as name resolution.
We must translate the pathname one step at a time to allow for symbolic
links.
Every process is associated with a current directory. The low
level name is evaluated by chdir().If we follow a symbolic link to
a location and try to "cd ..", we won't follow the symbolic link back to
our original location -- the system doesn't remember how we got there,
it takes us to the parent directory.
The ".." relationship superimpsoes a Directed Acyclic Graph(DAG) onto
the directory structure, which may contain cycles via links.
Have you ever seen duplicate listings for the same page in Web searche
ngines? This is because it is impossible to impose a DAG onto Web space
-- not only is it not a DAG on any level, it is very highly connected.
Each directory is created with two implicit components
- "." and ".."
- path to the root is obtained by travelling up ".."
- getwd() and pwd (shell) report the current directory
- "." allows you to supply current working directory to system calls
without calling getwd() first
- relative names remain valid, even if entire tree is relocated first
- "." and ".." are the same only for the root directory
Directory Entries
What exactly is inside of each directory entry aside form the file or
directory name?
UNIX directory entries are simple: name and inode #. The inode contains
all of the metadata about the file -- everything you see when you type
"ls -l". It also contains the information about where (which sectors)
on disk the fiel is stored.
MS-DOS directory entries are much more complex. They actually contain
the meta-data about the file:
- name -- 8 bytes
- extension -- 3 bytes
- attribes (file/directory/volume label, read-only/hidden/system) --
byte
- reserved -- 10 bytes (used by OS/2 and Windows 9x)
- time -- 2 bytes
- date -- 2 bytes
- cluster # -- 2 bytes (more soon)
- size -- 4 bytes
Unix keeps similar information in the inode. We'll discuss the inode in detail
very soon.
File System Operations
File system operations generally fall into one of three categories:
- Directory operations modify the names space of files.
Examples include mkdir(), rename(), creat(), mount(),
link() and unlink()
- File operations obtain or modify the characteristics of objects.
Examples include stat(), chmod(), and chown().
- I/O operations access the contents of a file. I/O operations,
unlike file operations, modify the actual contents of the file,
not metadata associated with the file. Examples include read(),
write(), and lseek(). These operations are typically much longer
than the other two. That is to say that applications spend much
more time per byte of data performing I/O operations than directory
operations or file operations.
From open() to the inode
The operating system maintains two data structures representing the state of
open files: the per-process file descriptor table and the system-wide
open file table.
When a process calls open(), a new entry is created in the open file table.
A pointer to this entry is stored in the process's file descriptor table.
The file descriptor table is a simple array of pointers into the open
file table. We call the index into the file descriptor table a file
descriptor. It is this file descriptor that is returned by open().
When a process accesses a file, it uses the file descriptor to index
into the file descriptor table and locate the corresponding entry in the
open file table.
The open file table contains several pieces of information about each
file:
- the current offset (the next position to be accessed in the file)
- a reference count (we'll explain below in the section about fork())
- the file mode (permissions),
- the flags passed into the open() (read-only, write-only, create, &c),
- a pointer to an in-RAM version of the inode (a slightly light-weight
version of the inode for each open file is kept in RAM -- others are
on disk), and a structure that contains pointers to all of the .
- A pointer to the structure containing pointers to the functions
that implement the behaviors like read(), write(), close(),
lseek(), &c on the file system that contains this file. This is the
same structure we looked at last week when we discussed the
file system interface to I/O devices.
Each entry in the open file table maintains its own read/write pointer
for three important reasons:
- Reads by one process don't affect the file position in another
process
- Write are visible to all processes, if the file pointer subsequently
reaches the location of the write
- The program doesn't have to supply this information each call.
One important note: In modern operating systems, the "open file table" is
usually a doubly linked list, not a static table. This ensures that it
is typically a reasonable size while capable of accomodating workloads that
use massive numbers of files.
Session Semantics
Consider the cost of many reads or writes may to one file.
- Each operation could require pathname resolution, protection
checking, &c.
- Implicit information, such as the current location (offset) into the
file must be maintained,
- Long term state must also be maintained, especially in light of the
fact that several processes using the file might require different
view.
Caches or buffers may need to be initialized
The solution is to amortize the cost of this overhead over many operations
by viewing operations on a file as within a session. open() creates a session
and returns a handle and close() ends the session and destroys the state.
The overhead can be paid once and shared by all operations.

Consequences of Fork()ing
In the absence of fork(), there is a one-to-one mapping from the file
descriptor table to the open file table. But fork introduces several
complications, since the parent task's file descriptor table is cloned.
In other words, the child process inherits all of the parent's file
descriptors -- but new entries are not created in the system-wide open
file table.
One interesting consequence of this is that reads and writes in one
process can affect another process. If the parent reads or writes, it will
move the offset pointer in the open file table entry -- this will affect the
parent and all children. The same is of course true of operations performed
by the children.
What happens when the parent or child closes a shared file descriptor?
- remember that open file table entries contain a reference count.
- this reference count is decremented by a close
- the file's storage is not reclaimed as long as the reference count
is non-zero indicating that an open file entry to it exists
- once the reference count reaches zero, the storage can be reclaimed
- i.e., "rm" may reduce the link count to 0, but the file hangs around
until all "opens" are matched by "closes" on that file.
Why clone the file descriptors on fork()?
- it is consistent with the notion of fork creating an exact copy of the
parent
- it allows the use of anonymous files by children. The never
need to know the names of the files they are using -- in fact, the
files may no longer have names.
- The most common use of this involves the shell's implementation of I/O
redirection (< and >). Remember doing this?
Memory-Mapped Files
Earlier this semester, we got off on a bit of a tangent and discussed
memory-mapped I/O. I promied we'd touch on it again -- and now seems
like a good time since we just talked about how the file system maintains
and access files. Remember that it is actually possible to hand
a file over to the VMM and ask it to manage it, as if it were
backing store for virtual memory. If we do this, we only use the
file system to set things up -- and then, only to name the file.
If we do this, when a page is accessed, a page fault will occur, and the
page will be read into a physical frame. The access to the data in file
is conducted as if it were an access to data in the backing-store. The
contents of the file are then accessed via an address in virtual memory.
The file can be viewed as an array of chars, ints, or any other primitive
variable or struct.
Only those pages that are actually used are read into memory. The pages
are cached in physical memory, so frequently accessed pages will not need
to be read from external storage each access. It is important to realize
that the placement and replacement of the pages of the file in physical
memory competes with the pages form other memory mapped files and those
from other virtual memory sources like program code, data, &c and is
subject to the same placement/replacement scheme.
As is the case with virtual memory, changes are written upon page-out and
unmodified pages do not require a page-out.
The system call to memory map a file is mmap(). It returns a pointer
to the file. The pages of the file are faulted in as is the case
with any other pages of memory. This call takes several parameters.
See "man mmap" for the full details. But a simplified version is this:
void *mmap (int fd, int flags, int protection)
The file descriptor is associated with an already open file. In this
way the filesystem does the work of locating the file. Flags specifies the
usual type of stuff: executable, readable, writable, &c. Protection is
something new.
Consider what happens if multiple processes are using a memory-mapped
file. Can they both share the same page? What if one of them changes
a page? Will each see it?
MAP_PRIVATE ensures that pages are duplicated on write, ensuring that
the calling process cannot affect another process's view
of the file.
MAP_SHARED does not force the duplication of dirty pages -- this implies
that changes are visible to all processes.
A memory mapped file is unmapped upon a call to munmap(). This call destroys
the memory mapping of a file, but it should still be closed using close()
(Remember -- it was opened with open()). A simplified interface follows.
See "man munmap" for the full details.
int munmap (void *address) // address was returned by mmap.
If we want to ensure that changes to a memory-mapped file have been committed
to disk, instead of waiting for a page-out, we can call msync(). Again,
this is a bit simplified -- there are a few options. You can see "man
msync" for the details.
int msync (void *address)
Cost of Memory Mapped Access To Files
Memory mapping files reduces the cost of accessing files imposed by the
need for traditional access to copy the data first from the device into
system space and then from system space into user space.
BUt it does come at another, somewhat interesting cost. Since the file
is being memory mapped into the VM space, it is competing with regular
memory pages for frames. That is to say that, under sufficient memory
pressure, access to a meory-mapped file can force the VMM to push a
page of program text, data, or stack off to disk.
Now, let's consider the cost of a copy. Consider for example, this
"quick and dirty" copy program:
int main (int argc, char *argv)
{
int fd_source;
int fd_dest;
struct stat info;
unsigned char *data;
fd_source = open (argv[1], O_RDONLY);
fd_dest = open (argv[2], O_WRONLY | O_CREAT | O_TRUNC, 0666);
fstat (fd_source, &info);
data = mmap (0, info.st_size, PROT_READ, MAP_SHARED, fd_source, 0);
write (fd_dest, data, info.st_size);
munmap (data, info.st_size);
close (fd_source);
close (fd_dest);
}
Notice that in copying the file, the file is viewed as a collection
of pages and each page is mapped into the address space. As the
write() writes the file, each page, individually, will be faulted into
physical memory. Each page of the source file will only be accessed once.
After that, the page won't be used again.
The unfortunate thing is that these pages can force pages that are
likely to be used out of memory -- even, for example, the text area
of the copy program. The observation is that memory mapping files
is best for small files, or those (or parts) that will be frequently
accessed.
Storage Management
The key problems of storage management include:
- Media independence (floppy, CD-ROM, disks, &c)
- Efficient space utilization (minimize overhead)
- Growth -- both within a file and the creation of new files
These problems are different in several ways from the problems we encountered
in memory management:
- I/O devies are so slow that the overhead of accessing more complex
data structures like linked lists can be overlapped with the I/O
operation itself. This makes the cost of this type of CPU/main memory
operation almost zero.
- Logical contiguity need not imply physical contiguity. The bytes
of a file may be stored any number of ways in physical media, yet we
view them in order and contiguously.
- The equivalent of the virtual memory page table can effectively be
stored entirely on disk and requires no hardware support
Blocks and Fragmentation
During our discussion of memory management, we said that a byte was the
smallest addressable unit of memory. But our memory management systems
created larger and more convenient memory abstractions -- pages and/or
segments. The file system will employ similar medicine.
Although the sector is the smallest addressable unit in hardware, the
file system manages storage in units of multiple sectors. Different
operating systems give this unit a different name. CPM called it
an extent. MS-DOS called it a cluster UNIX systems generally
call it a block. We'll follow the UNIX nomenclature and call it a block.
But regardless of what we call it, in some sense it becomes as logical
sector. Except when interacting with the hardware, the operating
system will perform all operations on whole blocks.
Internal fragmentation results as a result of allocating storage in
whole block units -- even when less storage is requested. But, much as
was the case with RAM< this approach avoids external fragmentation.
Key Differences from RAM Storage Management
- The variance in the size among files is much greater than the
variance of the sizes among processes. This places additional
demands on the data structures used to manage this space.
- Persistent storage implies persistent mistakes. The occasional
memory bug can't be solved by "rebooting the file system."
- Disk access (and access to most other media) is much slower
than RAM access -- this gives us more CPU time to make decisions.
Storage Allocation
Now that we've considered the role of the file system and the characteristics
of the media that it manages, let's consider storage allocation
During this discussion we will consider several different policies and
data structures used to decide which disk blocks are allocated to a
particular file.
Contiguous Allocation
Please think back to our discussion of memory management techniques.
We began with a simple proposal. We suggested that each unit of data
could be stored contiguously in physical memory. We suggested that this
approach could be managed using a free list, a placement policy such
as first-fit, and storage compaction.
This simple approach is applicable to a file system. But, unfortunately,
it suffers from the same fatal shortcomings:
- External fragmentation would result from small, unallocatable
"left over" blocks.
- Solving external fragmentation using compaction is possible and
wouldn't suffer from the aliasing problems that plague RAM
addressing. But, unfortunately, the very slow speed of most
non-volatile media, such as disks, makes this approach to
expensive to be viable.
- File growth would create a mess, because it might require
relocating the entire file.
- (Write-once media, such as CD-ROMs, are somewhat of an exception).
Linked Lists
In order to eliminate the external fragmentation problem, we need
to break the association between physical contiguity and logical contiguity
-- we have to gain the ability to satisfy a request with non-adjacent
blocks, while preserving the illusion of contiguity. To accompilish this
we need a data structure that stores the information about the logical
relationship among the disk blocks. This data structure must answer the
question: Which phyical blocks are logically adjacent to each other.
IN many ways, this is the same problem that we had in virtual memory --
we're trying to establish a virtual file address space for each file,
much like we did a virtual address space for each process.
One approach might be to call upon our time-honored friend the linked
list. The linked lists solves so many problems -- why not this one?
We could consider the entire disk to be a collection of linked lists,
where each block is a node. Specifically, each block could contain a
pointer to the next block in the file. But this approach has problems also:
Well, unfortunately, the linked list isn't the solution, this time:
- The blocks no longer hold only file data; they must now be correctly
interpreted each time they are accessed
- Non-sequential access is very slow, because we must
sequentially follow the pointers
File Allocation Table
Another approach might be to think back to our final solution for RAM
-- the page table. A page table-proper won't work for disk, because
each process does not have its own mapping from logical addresses to
physical addresses. Instead this mapping is universal across the entire
file system.
Remember the inverted page table? This was a system-wide mapping.
We could apply a similar system-wide mapping in the file system.
Actually, it gets easier in the file system. We don't need a complicated
hashing system or a forward mapping on disk. Let's consider MS-DOS.
We said that the directory entry associated the high-level "8 + 3" file
name assigned by the user with a low-level name, the number of the first
cluster populated by the file. Now we can explain the reason for this.
MS-DOS uses an approach similar to an inverted page table. It maintains
a table with one entry for each cluster on disk. Each entry contains a
pointer to the cluster that logically follows it. When a directory
entry is opened, it provides the address (cluster number) of the first
cluster in the corresponding file. This number is used as an index into
the mapping table called the File Allocation Table, a.k.a FAT.
This entry provides the number of the next cluster in the file. This process
can be repeated until the entry in the table corresponding to the last
cluster in the file is inspected -- this entry contains a sentinel value,
not a cluster address.
A compilicated hash is not needed, because the directory tree structure
provides the mapping. We don't need the forward mapping, because all
clusters must be present on disk -- (for the most part) there is no
backing store for secondary storage. To make use of this system, the only
"magic" required is a priori knowledge as to the whereabouts of the
FAT on disk (actually MS-DOS uses redundant FAT tables, with a write-all,
read one policy).
But this approach also has limitations:
inode Based Allocation
UNIX uses a more sophiticated and elogant system than MS-DOS. It is based
on a data structure known as the inode.
There are two important characteristics of the i-node approach:
- A per-file forward mapping table is used, instead of the
system-wide FAT table.
- An adapatation of the multi-level page table scheme is used to
effeciently support a wide range of file sizes and holes.
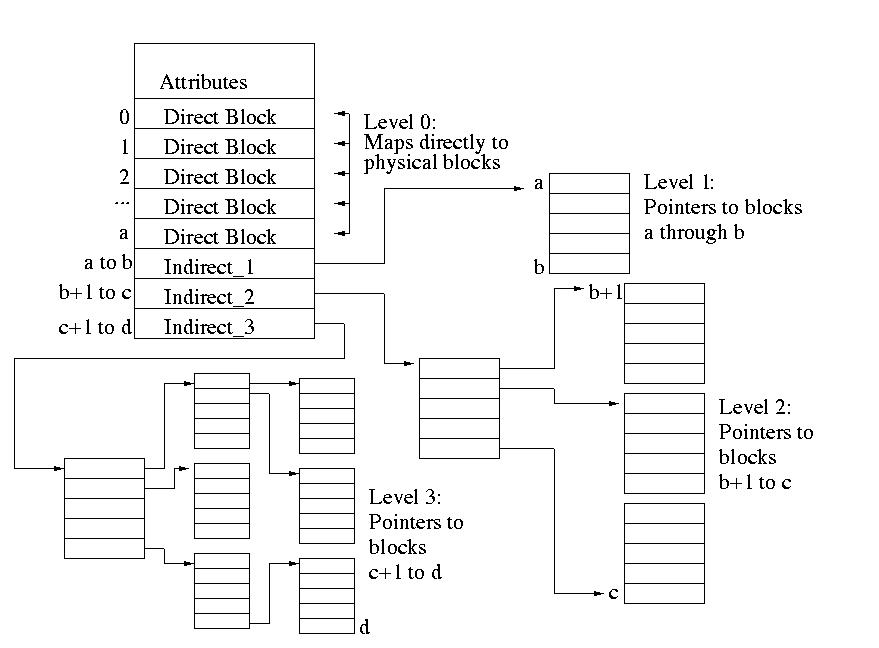
Each level-0 or outermost inode is divided into several different fields:
- File attribute: most of the good stuff that ls -l reports
is stored here
- Direct mappings: Entries containing direct forward mappings.
These mappings provide a mapping from the logical block number to the
location of the physical block on disk
- Indirect_1 Mappings: Entries containing indirect mapping
requiring one level of indirection. These mappings map a logical
block number to a table of direct forward mappings as described above. This table is then used to map from the logical block number to the
physical block address.
- Indirect_2 Mappings: Entries containing indirect mappings
requiring two levels of indirection. These mappings map a logical
block number to a table containing Indirect_1 mappings as described
above
- Indirect_3 Mappings: Entries containing mappings requiring
three levels of indirection. These mappings map a logical block
number to a table containing Indirect_2 mappings as described above.
Files up to a certain size are mapped using only the direct mappings.
If the file grows past a certain threshold, then Indirect_1 mappings are
also used. As it keeps growing, Indirect_2 and Indirect_3 mappings are
used. This system allows for a balance between storage compactness in
secondary storage and overhead in the allocation system. In some sense,
it amounts to a special optimization for small files.
Estimating Maximum File Size
Given K direct entries and I indirect entries per block, the biggest file
we can store is (K + I + I2 + I3 ) blocks.
If we would need to allocate files larger than we currently can, we
could reduce the number of Direct Block entries and add an Indirect_4 entry.
This process could be repeated until the entire table consisted of indirect
entries.